学习索引
by xiewajueji
learning index是一个非常有争议的东西,批评者觉得这玩意缺少有效的开源实现,不合适的数据集和缺少标准的benchmark组件。但这玩意的好处就是可以针对不同的情况做不同的事,使得用更少的代价做更多的事情。
背景
统计学习三要素为\(方法=模型+策略+算法\),模型是\(Y = f(X)\),策略是由\(L(Y, f(X))\)算出的\(R(f)\),算法是有限步骤找出使R(f)最小的有限步骤。监督学习主要解决的问题有分类问题,标注问题,还有回归问题。learning index属于监督学习中的回归问题。
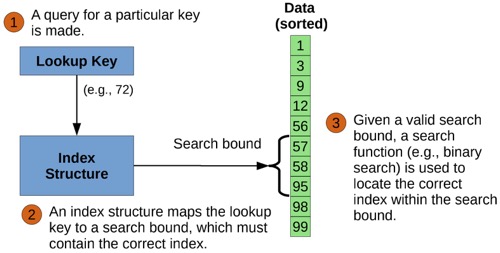
learning index的作用是在一个排好序的数组中查找第一个大于等于输入key的Entry的范围,即缩小查找的范围。
\[\forall x \in Z [I(x) = (lo, hi) \rightarrow D_{lo} \le LB(x) \le D_{hi}]\]假设我们训练的模型为\(A(X)\),误差率为\(\lambda\),排序数据集合为\(D\)。
\[I_A(x) = (A(x) - |D| * \lambda, A(x) + |D| * \lambda)\]模型
Recursive model indexes(RMI)
\[A(x) = f_2^{\lfloor {B * f_1(x) / |D|} \rfloor}(x)\]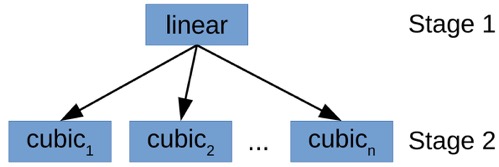
先训练\(f_1\)再训练\(f_2\)
Radix spline indexes(RS)
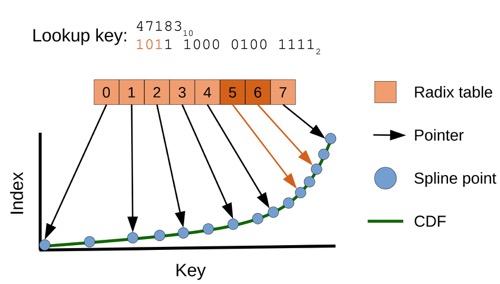
不用训练
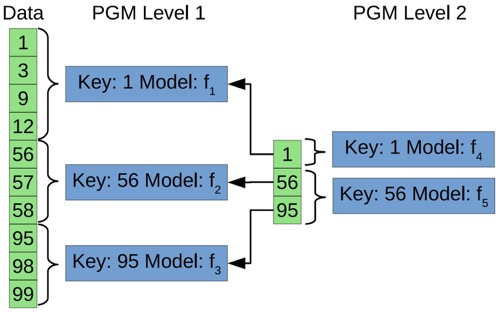
Piecewise geometric model indexes(PGM)
这玩意是RMI的特化版
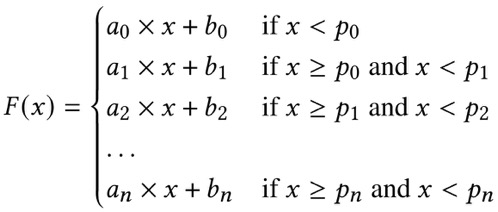
问题
Learning Index依赖于单个有序数组,即单调递增性,这样可能能够很简单的做线性拟合。如果是多个有序数组,一是没法更新,二是模型的训练难度随着模型的复杂度指数上升。
\(key \rightarrow i_{th}entry\) 比 \(key \rightarrow offset\) 更好拟合,因为offset没有数学意义,所以数组内的Entry要是定长的才能随机访问。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
struct PersistentPointer { // total 16B
uint64_t file_no; // 8B
uint64_t offset; // 8B
};
struct MetaBlock { // total 256B
std::bitset<1024> key_inline; // 128B
std::bitset<1024> value_inline; // 128B
};
using InlinePayload = char[sizeof(PersistentPointer)];
union Payload { // total 16B
PersistentPointer pointer;
InlinePayload inline_payload;
};
struct Entry { // total 32B
Payload key; // 16B
Payload value; // 16B
};
union SuperBlock { // total 256B
char padding[256]; // 256B
struct {
uint64_t magic_number;
uint64_t file_no;
FileType file_type;
uint64_t nb_entry;
uint64_t crct64;
};
};
struct EntryBlock { // total 256B
Entry entry[8]; // 256B
};
union ContainerBlock {
char padding[256];
};
// | super block | meta block | ... | entry block | ... |
// | super block | container block | ... |
constexpr size_t table_prefix_length = 20;
using table_prefix_t = char[table_prefix_length];
struct HashMap {
std::map<table_prefix_t, table_meta> map;
};